
Apache Storm Word Count¶
Apache Storm¶
Apache Storm is a distributed stream processing engine. Storm creates a directed acyclic graph (DAG) which consists of “spout” and “bolt” graph vertices which handle the streaming and processing of data. As Storm processes continuous streaming data, it is configured to run infinitely until explicitly terminated.
These are the things we will look at in this tutorial:
- WordCount program
- Download Apache Storm and set it up on your machine
- Run WordCount
WordCount example¶
WordCount is a simple streaming example where Storm is used to keep track of the words and their counts streaming in. This example is included in the Storm distribution. The source code can be found in the examples source code.
examples/storm-example/src/main/java/admicloud/storm/wordcount/WordCountTopology.java
In this example there are three processing units arranged in the graph.
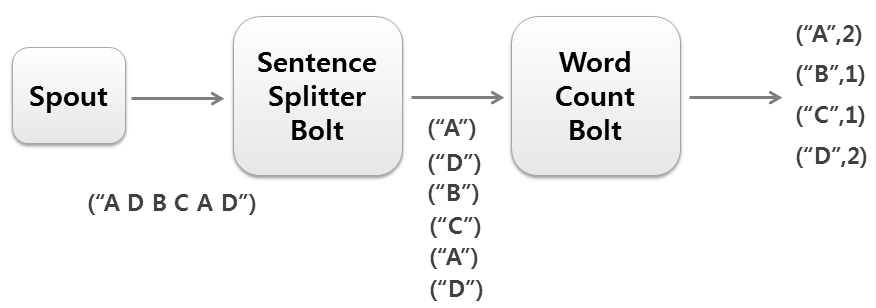
RandomSentenceSpout generates random sentences. SplitSentence splits these sentences into words, which are sent to the WordCount bolt where the count is kept.
Here is the source code of WordCount.
RandSentenceSpout¶
First it generates a random sentence and emits it to the Splitter.
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
Random _rand;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)];
_collector.emit(new Values(sentence));
}
@Override
public void ack(Object id) {
}
@Override
public void fail(Object id) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
SplitSentence Bolt¶
Receives sentences and splits them into words. Words are emitted to the WordCount bolt.
public static class SplitSentence extends BaseBasicBolt {
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String sentence = tuple.getStringByField("sentence");
String words[] = sentence.split(" ");
for (String w : words) {
basicOutputCollector.emit(new Values(w));
}
}
}
WordCount Bolt¶
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
Building the Topology¶
This code arranges the components described earlier into a graph.
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
Storm Setup¶
Now let’s look at how to set up a Storm Cluster in your local machine. A Storm cluster needs to have Apache ZooKeeper running.
wget http://ftp.wayne.edu/apache/storm/apache-storm-1.0.1/apache-storm-1.0.1.tar.gz
tar -xvf apache-storm-1.0.1.tar.gz
Download and start ZooKeeper¶
wget http://apache.mirrors.pair.com/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
tar -xvf zookeeper-3.4.8.tar.gz
cd zookeeper-3.4.8
cp conf/zoo_sample.cfg conf/zoo.cfg
./bin/zkServer.sh start
Start Storm Cluster on Local machine¶
cd apache-storm-1.0.1
In one terminal, start the nimbus server.
./bin/storm nimbus
In another terminal, start the supervisor.
./bin/storm supervisor
In the 3rd terminal, start the Storm Web UI.
./bin/storm ui
The above command will start the Storm UI. You can visit
http://localhost:8080/index.html
to view the Storm cluster.
Run the example WordCount¶
Now open another terminal to run the Storm example WordCount.
First you need to build it
git clone https://github.com/ADMIcloud/examples.git
cd examples/storm-example
mvn clean install
This will build the jar file inside target folder.
cd ../apache-storm-1.0.1
./bin/storm jar ../../examples/storm-example/target/storm-example-1.0-jar-with-dependencies.jar admicloud.storm.wordcount.WordCountTopology WordCount
You can view the topology by going to the web browser.
http://localhost:8080/index.html
To kill the topology, use the following command:
./bin/storm kill WordCount